Speculative decoding is a technique used by Google, Anthropic, and Meta to achieve 2-3x faster LLM inference with mathematically identical outputs. A small draft model generates K candidate tokens cheaply, then a large target model verifies all of them in a single parallel forward pass. Accepted tokens are kept; the first rejected token is replaced by the target model's prediction. Key production tradeoffs include tokenizer matching (same-tokenizer pairs yield 1.5-3x speedup vs 1.5-1.9x for cross-tokenizer), and draft model size (a 1B drafter outperformed an 8B drafter due to overhead costs). Variants like EAGLE, Medusa, and self-speculative decoding (LayerSkip, SWIFT) eliminate the need for a separate draft model by using trained heads or early-layer skipping within the target model itself. Implementation is available via Hugging Face's `assistant_model` parameter and vLLM for production serving.
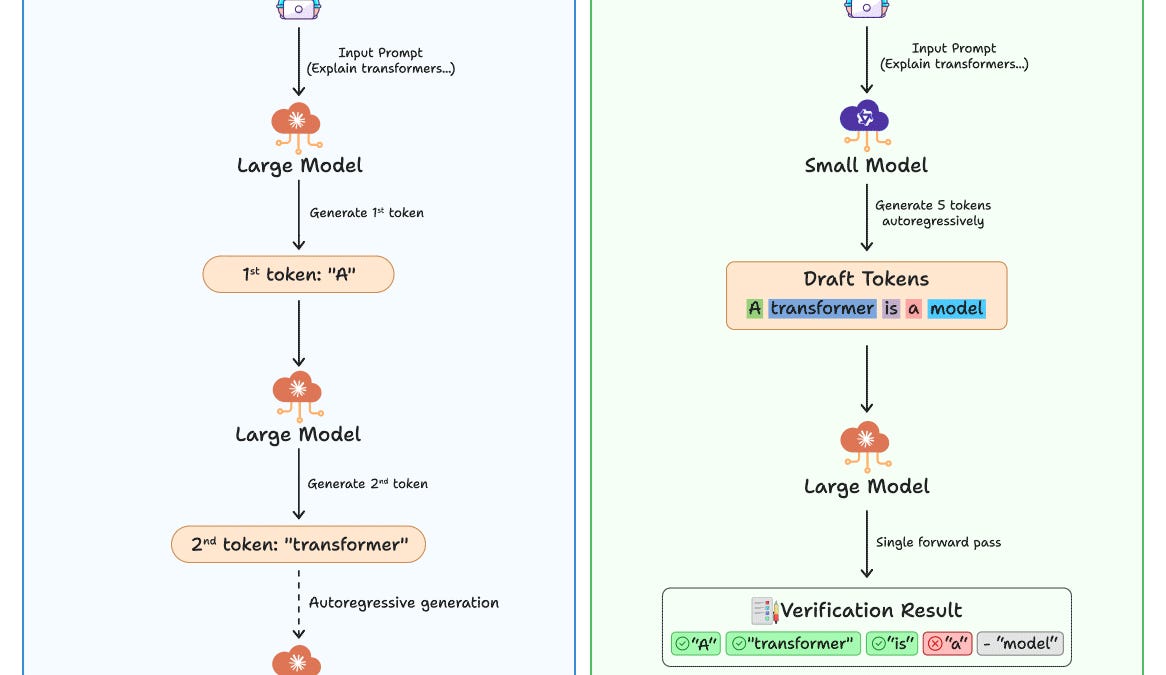
Table of contents
Fine-tune any LLM directly from Claude!Speculative decoding in LLMsP.S. For those wanting to develop “Industry ML” expertise:Sort: