Explores why traditional RAG pipelines fail for multi-source queries and introduces agentic context engineering as a solution. Breaks down the three critical layers needed: ingestion (handling auth, processing diverse data, incremental updates), retrieval (query expansion, multi-strategy search, authorization), and generation (citation-backed responses). Highlights that context retrieval for AI agents is fundamentally an infrastructure challenge requiring continuous sync, intelligent chunking, and hybrid search strategies rather than just embedding data into vector databases.
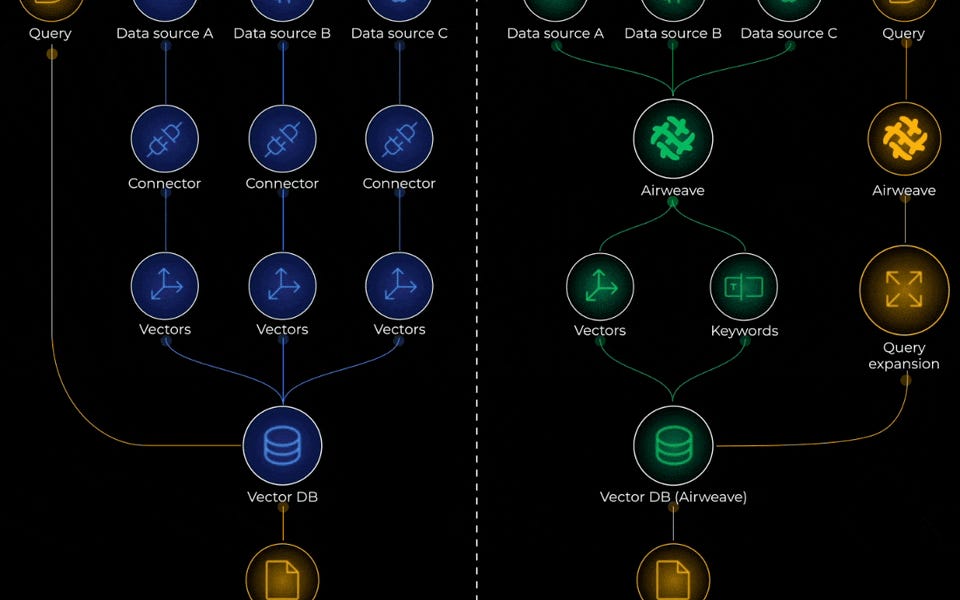
Table of contents
A new benchmark for reliable OCR is here!Manual RAG Pipeline vs Agentic Context EngineeringSort: