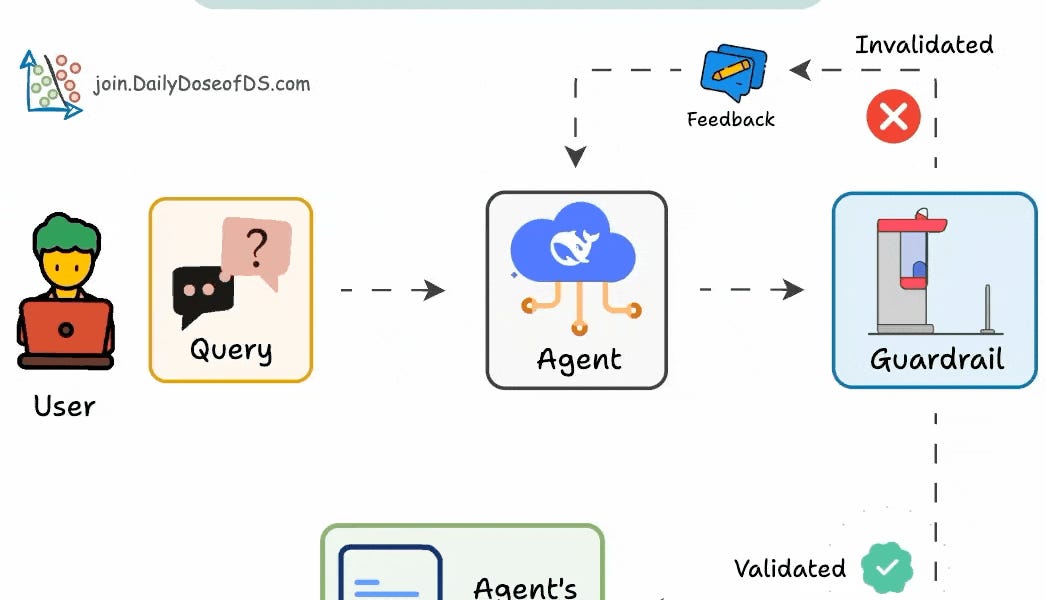
The post explains how reinforcement fine-tuning (RFT) enhances open-source LLMs, offering accuracy gains and efficient fine-tuning with few examples. It also details implementing guardrails for AI agents to prevent issues like hallucination and infinite loops. The guide walks through setting up validation checkpoints, limiting tool usage, and specifying fallback mechanisms with practical code examples.
Sort: