
Robert Youssef @rryssf_
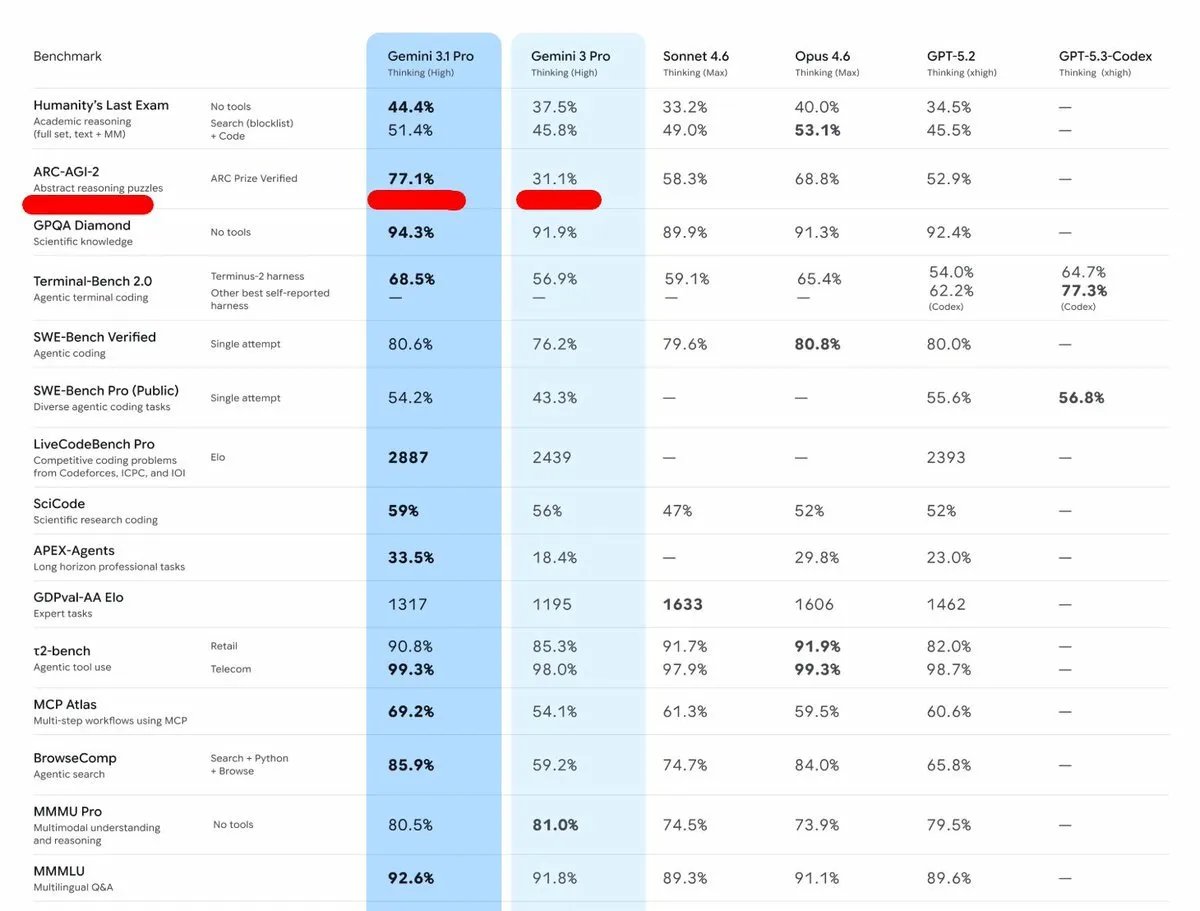
Gemini 3.1 Pro beats every model on exactly one benchmark. ties or loses on the other fifteen. and Google put that one number in bold 💀 look at the table. against Opus 4.6, Sonnet 4.6, GPT-5.2, the differences are tiny. 1-3% gaps. basically nothing. then you get to ARC-AGI-2: 77.1% next closest is Opus 4.6 at 68.8%. that's a huge gap on one single benchmark while everything else is neck and neck. that pattern only means one thing. they trained specifically for that test. if the model was genuinely smarter, you'd see improvements across the board. not one outlier and a bunch of ties. this is the real problem with benchmarks right now. labs pick the one eval they can win, optimize for it, then put it in bold on the announcement post. tomorrow a new benchmark drops, Gemini scores average on it, then six months later they magically improve on that one too. it's not progress. it's test prep.
Sort: