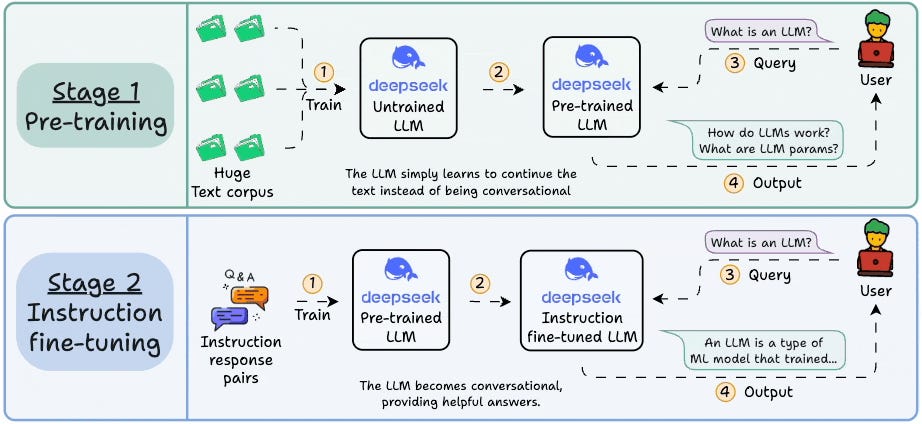
Part 3 of an LLMOps course is now available, covering attention mechanisms, transformer architectures, mixture-of-experts, and the fundamentals of pretraining and fine-tuning with hands-on code demos. LLMOps extends traditional MLOps principles to address the unique engineering challenges of managing large language models like Llama, GPT, and Claude in production, focusing on reliability, accuracy, security, and cost-effectiveness. The course aims to provide systems-level thinking for building production-ready LLM applications with clear explanations, examples, diagrams, and implementations.
Sort: