Group Relative Policy Optimization (GRPO) is a reinforcement learning method that fine-tunes large language models for math and reasoning tasks using deterministic reward functions, eliminating the need for labeled data. The process involves generating multiple candidate responses, assigning rewards based on deterministic functions, and using GRPO loss to update the model through backpropagation. A practical implementation demonstrates using UnslothAI and HuggingFace TRL to transform a base model into a reasoning-capable system, with reward functions that validate response format and correctness without manual labeling.
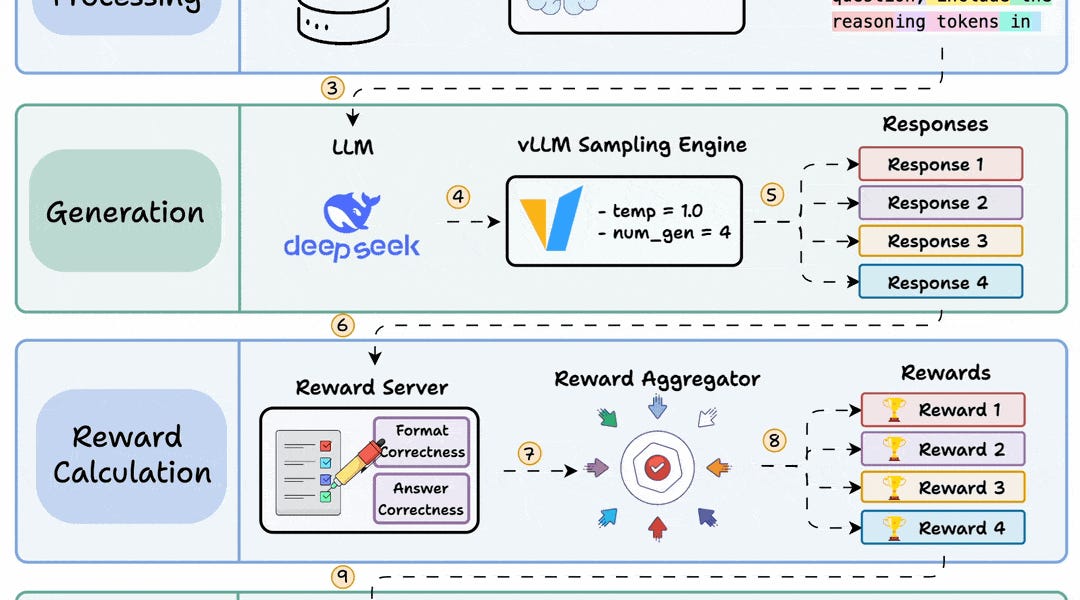
Table of contents
95% Agents die before production. The remaining 5% do this.Build a Reasoning LLM using GRPOSort: