OWASP ranks prompt injection as the #1 threat to LLM applications, yet most deployments rely solely on system prompt instructions as defense. Five composable, architectural defenses are presented: (1) labeling untrusted input with explicit delimiters or Base64 encoding, (2) instruction hierarchy assigning trust ranks to developer/user/third-party sources, (3) principle of least privilege by restricting agent tool access to only what's needed, (4) human-in-the-loop approval for sensitive actions, and (5) planner-executor separation where one model reasons over untrusted data without tool access and another executes a structured plan without seeing raw untrusted input. Layering all five provides the strongest protection, as no single defense is sufficient alone.
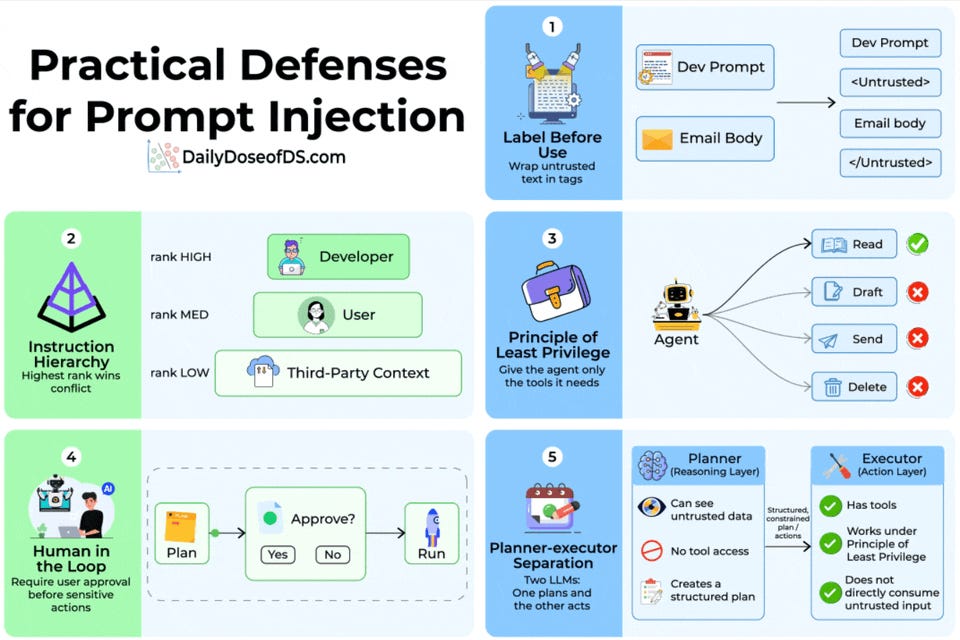
Table of contents
InsForge: The first backend built for AI coding agents Practical defenses for prompt injectionSort: