Multi-GPU training distributes deep learning workloads across multiple GPUs using four main strategies. Model parallelism splits model layers across GPUs for models too large for single devices. Tensor parallelism divides individual tensor operations across processors. Data parallelism replicates the model on each GPU while
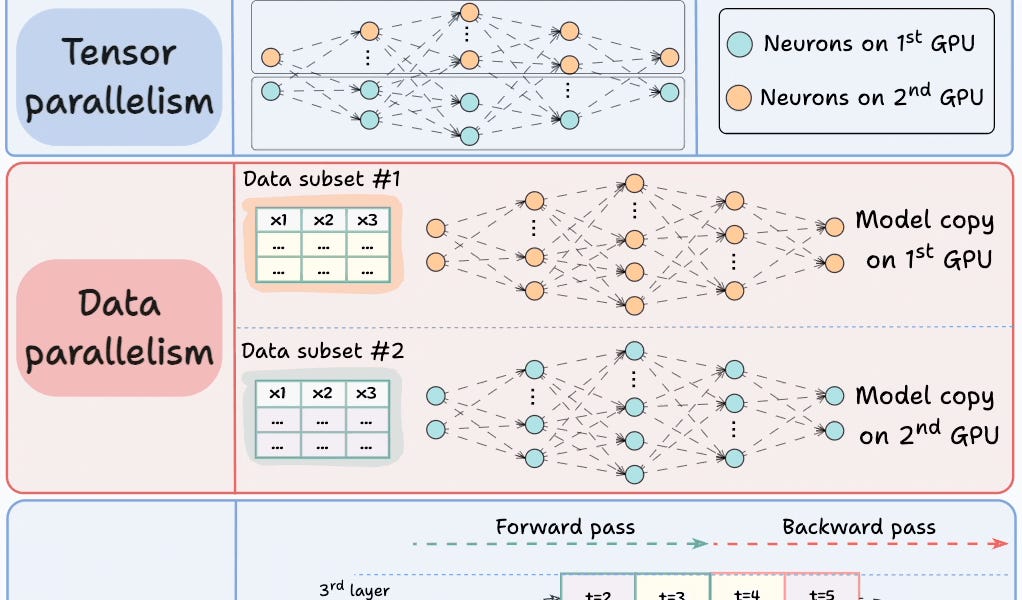
Table of contents
Get End-to-end API observability with Postman4 Strategies for Multi-GPU TrainingTrain LLMs 3× faster without any accuracy loss Sort: